4 Results
This chapter describes the results of each stage of the framework preparation and the validation approach used to verify its applicability and effectiveness on realistic data.
4.1 Tree segmentation network training results
The results of training a tree segmentation PointNet++ are challenging to evaluate on their own because there are no inherently good metrics that would put the performance into easily understandable numbers. As was mentioned in Section 3.4.3, during training model checkpointing is set up to track average validation accuracy – the proportion of points for which the final predicted label is correct. However, the predictions are quite noisy, resulting in low accuracies even for results that are not bad. Figure 4.1 shows the prediction on a sample from the validation dataset used to monitor the training process, and Figure 4.2 shows the same prediction in 3D. The accuracy of the model on the figures is 33.6%, and it is around the best accuracy of all the experiments I ran, excluding ones with simpler data.
Overall, the final model was selected less based on raw numbers such as maximum average validation accuracy or minimum average validation loss, but by expecting the visualizations of the predictions on a subset of samples from the validation dataset.
4.1.1 Effect of dropout augmentation
An essential part of the framework is training of the tree segmentation network on synthetic forest patches, which requires heavy use of augmentations to make the data look more realistic and make the model applicable to real-world data. The most important augmentation that addresses the selection bias present in the dataset of individual tree point clouds is the height-dependent dropout described in Section 3.4.2. It would undoubtedly be beneficial to conduct a comprehensive exploration of the effect this augmentation itself and its parameters have on the results of the tree segmentation task specifically and the framework overall. Unfortunately, this thesis does not go into that much detail on that topic because of the time constraints. Still, despite not being properly recorded for the purpose of comprehensive qualitative evaluation, there were many experiments ran with various parameters, and their results are summarized qualitatively below.
Not using the dropout augmentation at all makes the task of segmenting the patches significantly easier – almost all the trees are complete, with a clearly separable trunks. Average validation accuracies in the setup without the augmentation are significantly higher, and validation loss is significantly lower. However, this does not translate to improved results when applying the network to real data, since the training data looks very different when the augmentation is not applied. In such a setup, during inference the network essentially operates completely outside the distribution of its training dataset, making the task impossible and resulting in almost random assignment of IDs to the points.
The sigmoid used to calculate the probability threshold for the dropout is parametrized by scale, which controls how steep the increase in the probability is with height, and shift, which controls the position of the incline. Examples of threshold curves for different values of the parameters are shown in Figure 3.17 and Figure 3.18. Milder variations, which are characterized by lower positions of the incline and more gradual slopes, as in Figure 3.17, have similar effects to not using the augmentations at all. When not enough points are removed, the task remains simple, leading to higher training metrics and worse performance on real data. As the dropout becomes more aggressive, with the position of the incline higher and slopes steeper, as in Figure 3.18, the training data becomes more similar to the real data. It leads to the decrease in the average validation training accuracy and increase in values of the loss function during training, but the performance translates much better to the real data. At some point, the dropout becomes too aggressive, almost completely destroying the individual trees and making their shapes almost unrecognizable. The training metrics continue to decline, as the task becomes even more complicated, but so does the performance on real data, since the augmentation no longer makes the training data look similar to the real data.
The optimal parameters for the augmentation were selected by manual search. Automating their selection is not immediately available, since there are no direct metrics that tie the performance of the network during training to its performance on the validation data.
4.2 Attribute prediction model training results
To evaluate the performance of the attribute prediction models, 10-fold stratified cross validation was used, as well as a separate 40% hold-out set. For the tree species classification model, the stratification was performed using the labels directly. For the diameter at breast height regression model, the stratification was performed on the label split into 5 equal-width buckets across the range.
4.2.1 Tree species classification
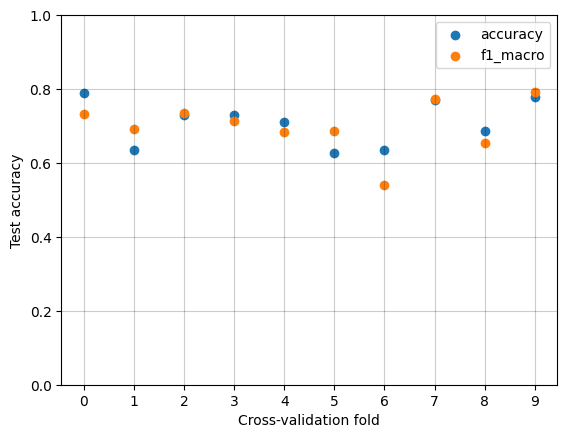
The tree species classification model was evaluated using accuracy and macro \(F_1\)-score (an average of \(F_1\)-scores across all the classes). Figure 4.3 shows out-of-fold metrics across all ten folds of cross-validation. The average accuracy is 0.71, with a standard deviation of 0.06. The average macro \(F_1\)-score is 0.70, with a standard deviation of 0.07. The model is overall relatively consistent across all ten folds, showing that the cross-validation metrics estimates are reliable.
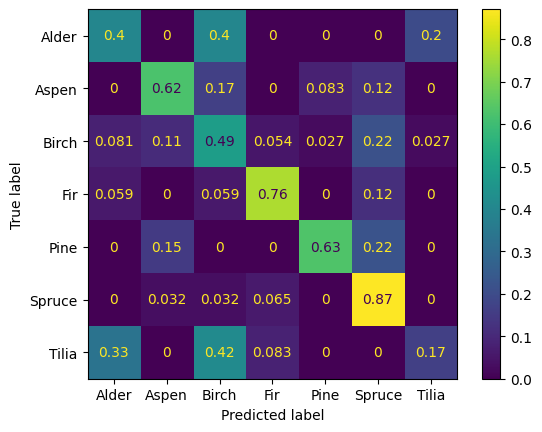
The holdout set was used to take a more in-depth look at the classification results. Figure 4.4 shows the confusion matrix for the holdout set, with values normalized by row. The set is relatively small – 158 examples, but enough to see some patterns emerge in the predictions. The best overall species is spruce, having the larges accuracy. All coniferous species have higher accuracies than all deciduous species. The model often confuses deciduous species, classifying alder as birch or tilia, aspen as birch, tilia as alder or birch. This behavior is to be expected, as the shapes of deciduous species are very similar to each other and are complex in general. The overall accuracy in the holdout set is 61%.
4.2.2 Diameter at breast height regression
Diameter at breast height regression model was evaluated using root mean squared error (RMSE), mean absolute error (MAE), and coefficient of determination \(R^2\). Formulas for the metrics are provided below, with \(y_i\) representing the true dbh value, \(\hat y_i\) – the corresponding prediction, and \(\overline y\) – the average dbh. The dataset here is smaller than the one for tree species classification because diameter at breast height is only available for trees from the Lysva field inventory, while species are available for all trees in the individual tree point cloud dataset, some of which are from other surveys in the region.
\[ \begin{aligned} \text{RMSE} &= \sqrt{\frac{1}{N} \sum_{i=1}^N (y_i - \hat y_i)^2} \\ \text{MAE} &= \frac{1}{N} \sum_{i=1}^N | y_i - \hat y_i | \\ R^2 &= 1 - \frac{\sum_{i=1}^N (y_i - \hat y_i)^2}{\sum_{i=1}^N (y_i - \overline y)^2} \end{aligned} \]
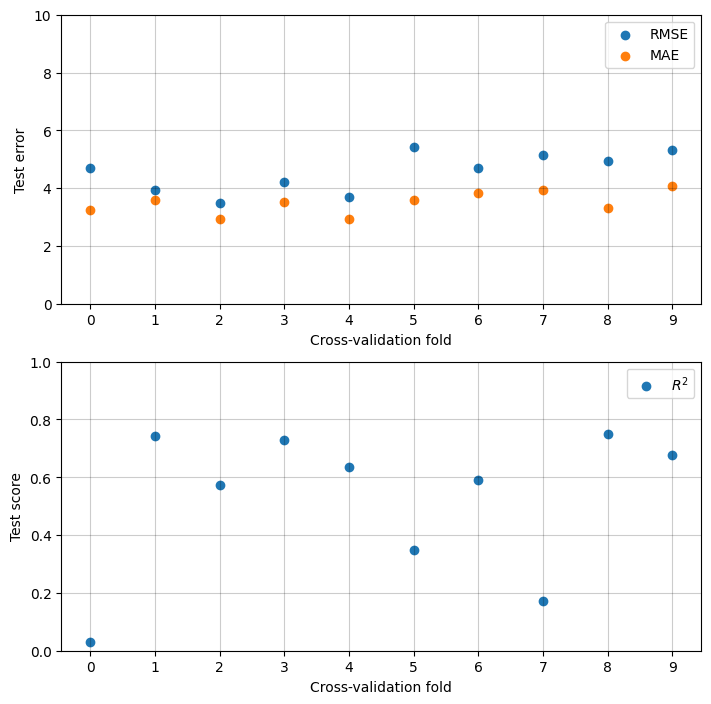
Figure 4.5 shows out-of-fold metrics across all ten folds of cross-validation. Both the mean squared error and the mean absolute error are stable across the folds, with average RMSE 4.55 centimeters with a standard deviation of 0.19 and average MAE 3.49 centimeters with a standard deviation of 0.38. Coefficient of determination \(R^2\) is less stable. Even though most folds have it around 0.6 to 0.8, there are two folds where it drops to below 0.2 and even close to 0, meaning that the model there is no better than predicting the mean dbh for every input. This drops the average \(R^2\) to 0.53 with a standard deviation of 0.24.
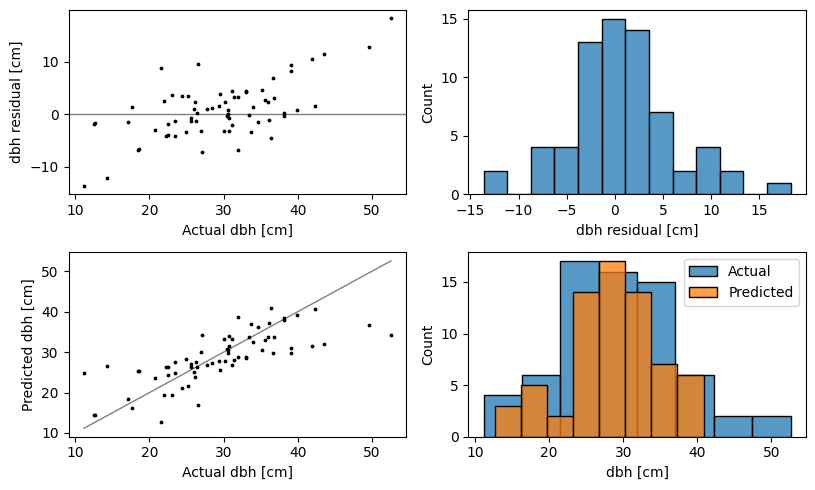
Similar to the classification model, the holdout set was used to take a more in-depth look at the regression results. Here the holdout set is even smaller than for regression – 68 samples. Figure 4.6 offers a collection of diagnostic visualizations aimed to help better understand the regression performance. On the top left is the residual plot, where the differences between the actual dbh and the predicted dbh are plotted against the actual dbh values. Ideally, the points should be around a horizontal line at zero, shown in black, without any patterns. This would mean that the size of the error does not depend on the value of dbh. The resulting dbh regression model shows a trend, which means it tends to overestimate low dbh values and underestimate high dbh values. A related plot is on the top right, showing the distribution of the residuals across the holdout set. It should be centered around zero and as narrow as possible. On the bottom left is a scatter plot of predicted dbh against the actual dbh. Ideally, this should be a 45-degree line, shown in black. Because of the underestimation on the high end and overestimation in the low end, the points seem to lie on a line with a smaller slope. Although most points are in the middle, where the line is followed a lot more closely. And, finally, a related plot on the bottom right, comparing distributions of the actual dbh and predicted dbh in the holdout set. The same lack of extreme can be observed. The final holdout set RMSE is 5.76 cm, MAE is 4.11, \(R^2\) is 0.52.
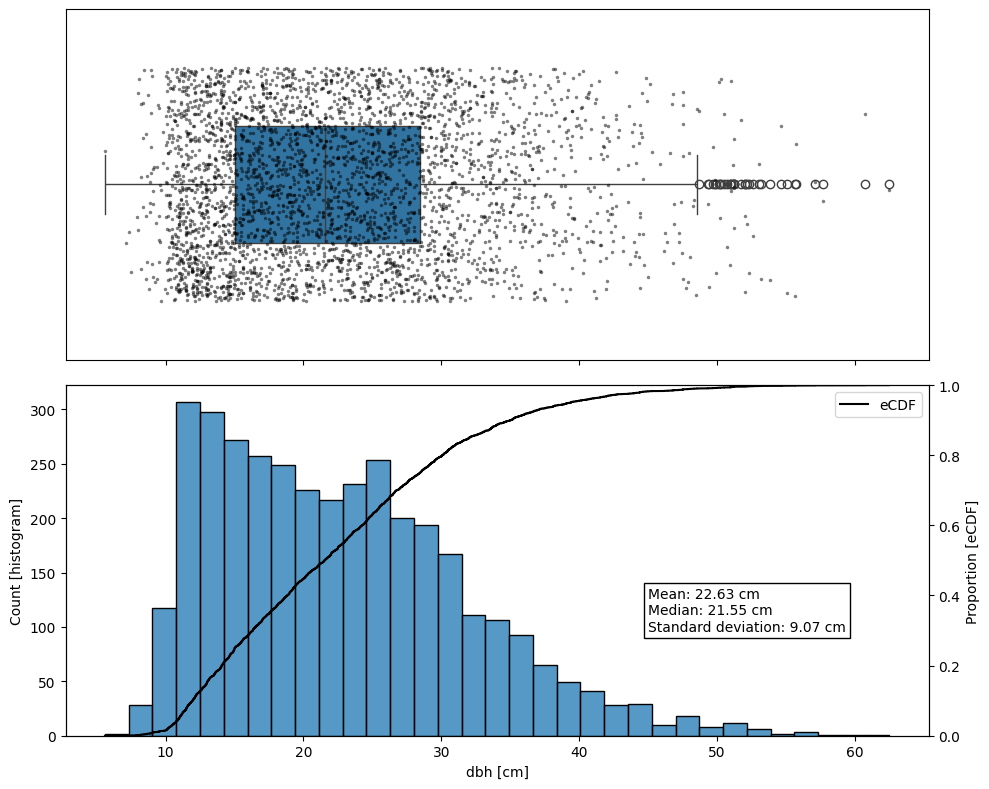
Figure 4.7 show the distributions of the field measured dbh in the full Lysva dataset for reference. On the top it show a boxplot with every individual observation plotted as a point, jittered along the Y axis to reduce overlap. On the bottom, a histogram and an empirical cumulative density function are shown, along with the mean, median, and standard deviation.
4.3 Validation on the Lysva field inventory data
To validate the framework, the results were evaluated on the Lysva field inventory dataset, described in Section 3.1. The mean X and Y coordinates of each segmented tree were calculated to convert the cloud into a set of points, where each point represents a candidate detected tree. The maximum height of the points in the cluster was used as the height of the detected tree. Then the algorithm described in Section 3.6 was applied to match the detected trees their corresponding the ground truth trees, if any. The matching algorithm was run with maximum distance between a detected tree candidate and a ground truth tree of 5 meters and maximum height difference of 3 meters (ignored for ground truth trees that do not have measured height). Then, precision, recall, and \(F_1\)-score were calculated for the detection results, and for the true positive matches the average distance between the detected tree and the actual tree, species classification accuracy and macro \(F_1\)-score, and diameter at breast height errors are calculated.
Table 4.1 shows the tree detection metrics. When interpreting the metrics, the reader is advised to keep in mind the limitations of the distance metric mentioned in Section 3.6, and instead focus on the \(F_1\)-score as the most informative metric. The overall average \(F_1\)-score for tree detection by the described system is 0.63. This approach thus outperforms the basic individual local maximum filter in tree detection in the Lysva region as reported in Dubrovin, Fortin, and Kedrov (2024) by 0.13.
| Plot | Tree count | Dominant type | Point density | Recall | Precision | F1-score | Distance |
|---|---|---|---|---|---|---|---|
| 1 | 420 | Deciduous | 31.7 | 0.83 | 0.63 | 0.72 | 0.77 |
| 2 | 365 | Deciduous | 47.9 | 0.61 | 0.72 | 0.66 | 0.81 |
| 3 | 332 | Deciduous | 40.3 | 0.63 | 0.49 | 0.56 | 0.85 |
| 4 | 261 | Coniferous | 33.5 | 0.85 | 0.50 | 0.63 | 1.06 |
| 5 | 208 | Coniferous | 14.2 | 0.68 | 0.55 | 0.61 | 0.97 |
| 6 | 290 | Coniferous | 39.1 | 0.80 | 0.52 | 0.63 | 0.83 |
| 7 | 408 | Deciduous | 41.9 | 0.65 | 0.62 | 0.63 | 0.85 |
| 8 | 341 | Coniferous | 35.5 | 0.87 | 0.57 | 0.69 | 0.93 |
| 9 | 459 | Coniferous | 42.1 | 0.56 | 0.65 | 0.60 | 0.92 |
| 10 | 518 | Deciduous | 42.9 | 0.42 | 0.92 | 0.58 | 0.99 |
| Average: | 0.69 | 0.62 | 0.63 | 0.90 |
Figure 4.8 shows the confusion matrix for species prediction calculated for true positive matches. Note that willow trees are not included, as the model has not seen any in the training data, and all pine predictions are counted as spruce instead. The pattern of the confusion matrix is similar to the evaluation on the holdout set. The overall accuracy is 66.1%. The overall macro \(F_1\)-score is 55.4%.
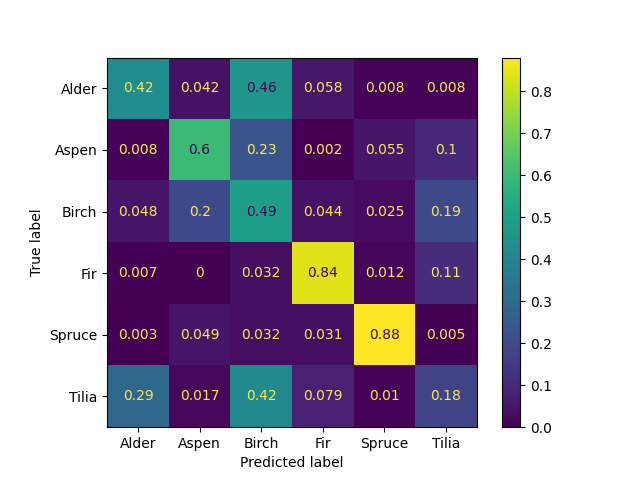
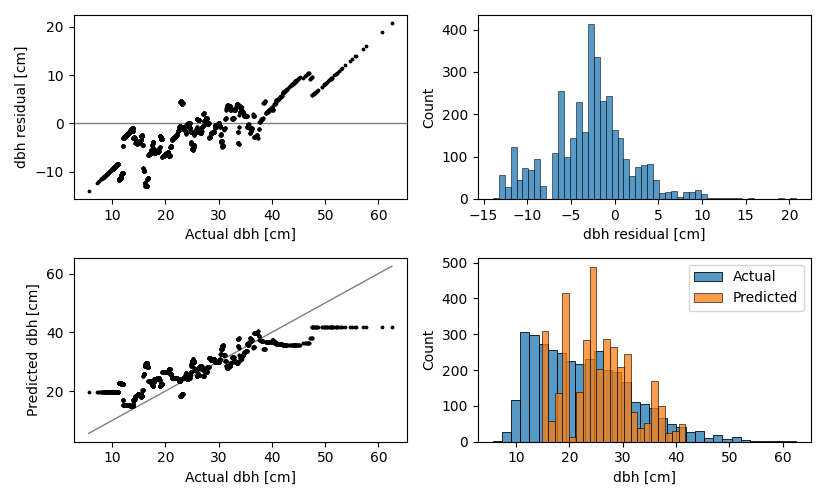
Figure 4.9 show the quality assessment plots for the results of diameter at breast height regression. It’s obvious from the plots that the individual tree dataset is not representative of the entire Lysva dataset in terms of dbh, as the range of dbh in there is not wide enough. The distributions show that the individual trees dataset has higher mean dbh values than the overall distribution, which makes the model eager to overestimate a lot. This effect is no doubt connected to the sampling bias mentioned in the description of the individual trees dataset: trees were selected by humans based on how easy they are to extract from a large point cloud. As the result, the predictions outside the range seen by the Random Forest are constant. Within the covered range, however, the behavior is similar to what was observed on the holdout set: a trend in the residual plot indicating over- and underestimation of low and high values, and errors close to zero near the middle of the range. The overall root mean squared error is 5.37 centimeters. The overall mean absolute error is 4.21 centimeters. The overall coefficient of determination \(R^2\) is 0.65.