| plot | tree_no | species | d1 | d2 | dbh | age | height | angle | comment | geometry |
|---|---|---|---|---|---|---|---|---|---|---|
| 7.0 | 111.0 | Birch | 23.0 | 23.0 | 23.00 | NaN | NaN | 0.0 | None | POINT (545784.419 6449359.132) |
| 5.0 | 136.0 | Fir | 23.5 | 23.0 | 23.25 | 90.0 | 17.5 | 0.0 | Rotten | POINT (545721.242 6449901.051) |
| 3.0 | 119.0 | Aspen | 36.1 | 42.1 | 39.10 | 89.0 | 25.5 | 0.0 | None | POINT (546630.326 6450158.241) |
| 9.0 | 345.0 | Spruce | 19.7 | 22.0 | 20.85 | NaN | 15.9 | 0.0 | None | POINT (546201.645 6449118.199) |
| 6.0 | 267.0 | Spruce | 12.9 | 12.9 | 12.90 | NaN | NaN | 0.0 | None | POINT (545568.842 6449407.13) |
3 Materials and methods
This chapter describes in detail used datasets, processing techniques and the methods, and comments on the reasoning behind the choices. The code of the project on my GitHub might be a helpful addition for that.
3.1 Lysva dataset
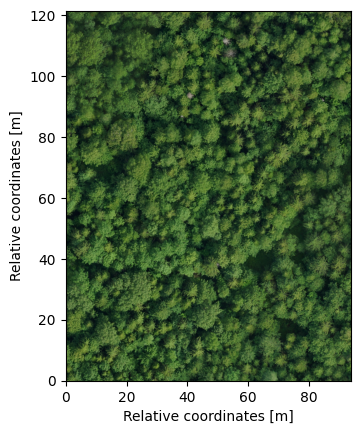
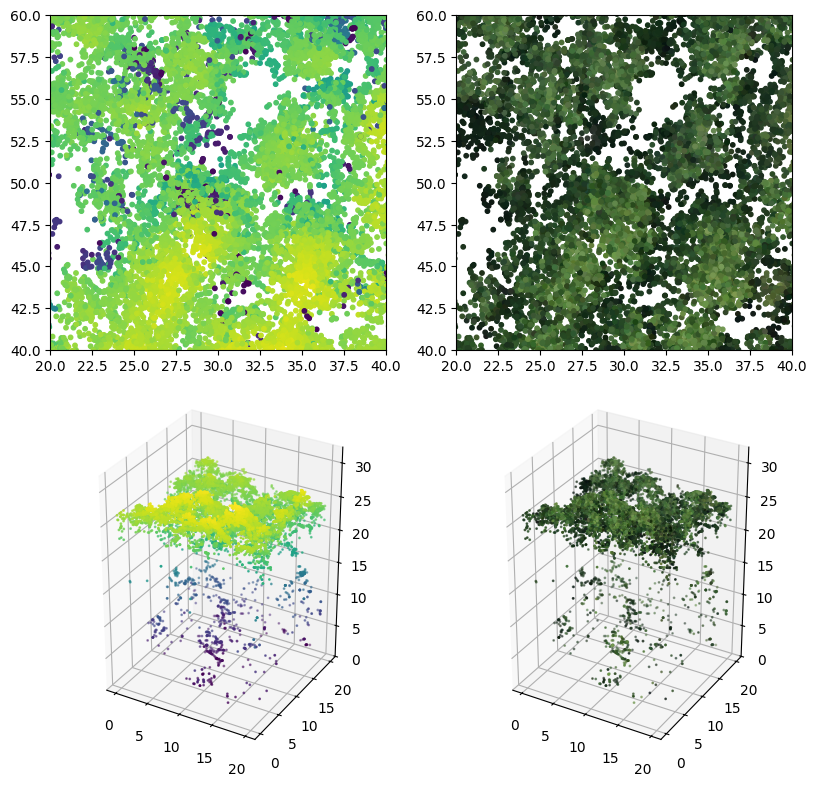
The main original dataset used in the study is the Lysva field inventory dataset, named by the closest town to its location. The dataset is released into open access with an accompanying paper that describes the data in detail and provides a basic baseline for individual tree detection (Dubrovin and Fortin 2024). The study area is located in Perm Krai, Russia, 86 kilometers to the east of Perm. The forest in the region is natural, with the average age of coniferous trees over 85 years and deciduous over 60 years. The dataset consists of a field inventory of 3600 trees across 10 rectangular ground plots 100 meters in lengths and 50 meters in width fully covered by a UAV LiDAR and RGB orthophoto surveys. Figure 3.1 shows the locations of the ground plots over the full size RGB orthophoto and a visualization of the field inventory for a single plot on top of the LiDAR point cloud. The low vegetation areas visible on the orthophoto are naturally regenerating old logging and agricultural sites. No artificial afforestation has been done in the area. Colored points represent trees, with different colors mapping to different species. The point cloud is visualized as a 2D scatter plot with points colored by height (darker points are lower, brighter points are higher, and points are unsorted – some lower points end up over higher ones). The baseline is a simple one-pass local maxima filter applied directly on the point cloud with a fixed window size.
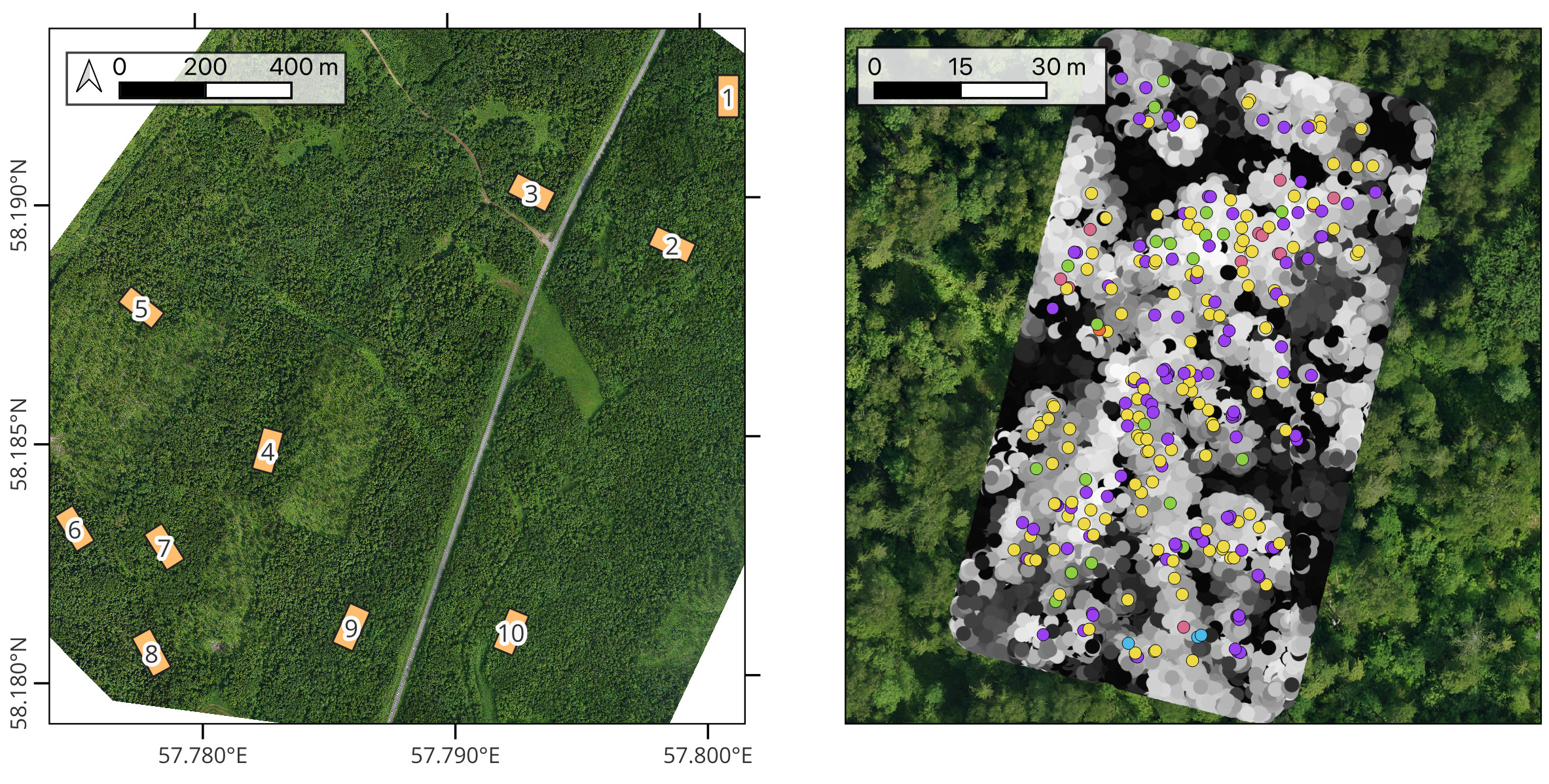
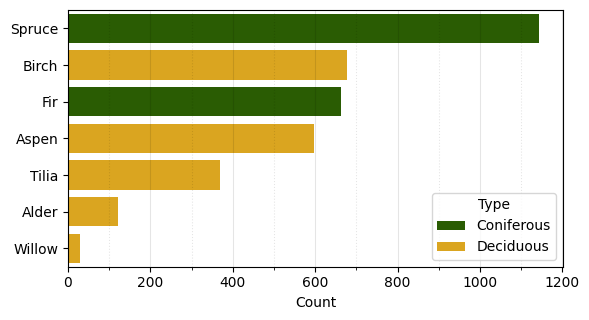
The field inventory is a tabular dataset where every row represents a single tree. According to the state-mandated requirements that were in place during the collection of the data, all trees with dbh starting from 6.1 centimeters were included. Table 3.1 shows a random sample of entries from the field inventory table. Every tree is represented by a point in UTM 40N coordinate reference system (EPSG:32640). The coordinates of the trees were determined using the South NTS-360R total station with a reflector prism using the closed traverse method. The total station measurements used two points basis determined using a dual-frequency South G1 Plus IMU GNSS receiver in RTK mode. The basis points were selected to have reliable satellite signal. The average error of coordinate measurements is 10 centimeters, with a maximum of 30 centimeters. Every tree has a species label and diameter at breast height (dbh), measured with calipers at 1.3 m from the ground at two perpendicular directions and averaged. Figure 3.2 shows the distribution of species in the data: the dominant species is spruce, but overall the trees are evenly split between deciduous and coniferous, 1793 and 1807 respectively, with seven species in total: spruce, birch, fir, aspen, tilia, alder, and willow. Approximately 20% of the trees have height data measured during the inventory, and 10% have ages measured on core samples, shown in the table in meters and years respectively.
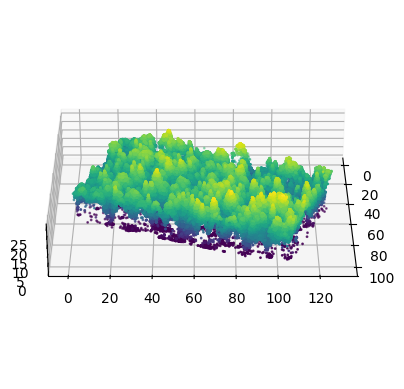
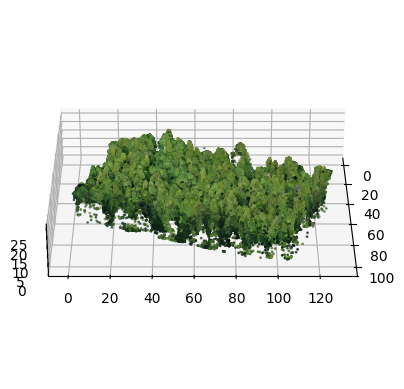
The LiDAR sensor used for the survey is AGM-MS3 produced by AGM Systems. It has 640 kHz acquisition rate, 300-meter range, and spatial accuracy of 3–5 centimeters. The raw point clouds were processed with the combination of the AGM ScanWorks software from the sensor vendor and the TerraScan software. The point clouds were preprocessed by removing duplicate points and high and low noise points. The duplicate removal was run with a threshold distance between points of 1 mm. Noise was removed by visually inspecting the point cloud and manually selecting height thresholds to cut off points that are lower than the ground or higher than the canopies. Ground point classification was performed and ground points were used to normalize height by subtracting the ground level from the Z coordinate of every point. Height normalization allows treating the Z coordinate as height above ground rather than the absolute elevation, which simplifies many subsequent steps. The camera used to collect raw digital images for creating the orthophoto is Sony A6000. Agisoft Metashape software was used to generate the orthophoto mosaic. A canopy-height map was created from the LiDAR point cloud and used as a reference for adjusting the planar coordinates of the orthophoto to align them. The resolution of the orthophoto is 7 centimeters per pixel. Figure 3.3 is a 3D visualization of the point cloud over plot number 10. It shows the unmodified point cloud on the left, with points colored by height above ground, and a point cloud enriched with color information by sampling the orthophoto at the planar coordinates of the points. Figure 3.4 shows the orthophoto for the same plot. The carrier UAV used for the LiDAR survey is DJI Matrice 600 Pro hexacopter. The speed during the survey was 10 meters per second. The UAV was configured to follow the terrain at 150 meter height using the SRTM elevation map as a reference (Farr and Kobrick 2000). The carrier UAV used for the orthophoto survey is the fixed-wing Geoscan 201 Geodesy. The speed during the survey was 16.6 meters per second. Figure 3.5 shows the UAVs used for the remote sensing data collections. Table 3.2 summarizes the sensor and platform characteristics, as well as some of the acquisition parameters.


| LiDAR survey | Orthophoto survey | |
|---|---|---|
| Sensor | AGM-MS3 | Sony A6000 |
| Resolution | 37 points/m² | 7 cm/px |
| Carrier UAV | DJI Matrice 600 Pro | Geoscan 201 Geodesy |
| Carrier UAV type | Rotary-wing (hexacopter) | Fixed-wing |
| Acquisition height | 150 m | 150 m |
| Acquisition speed | 10 m/s | 16.6 m/s |
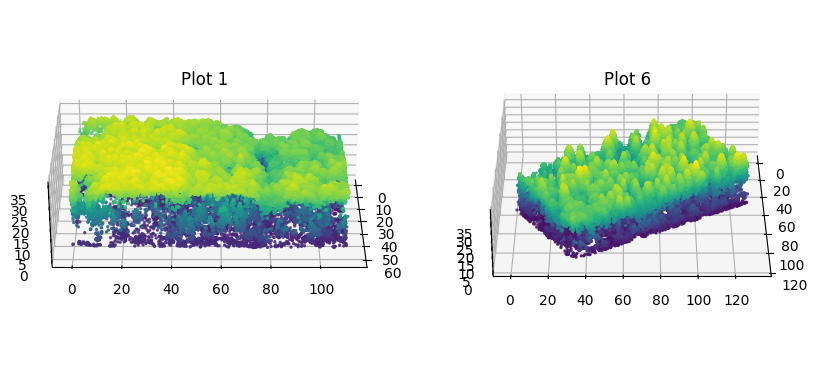
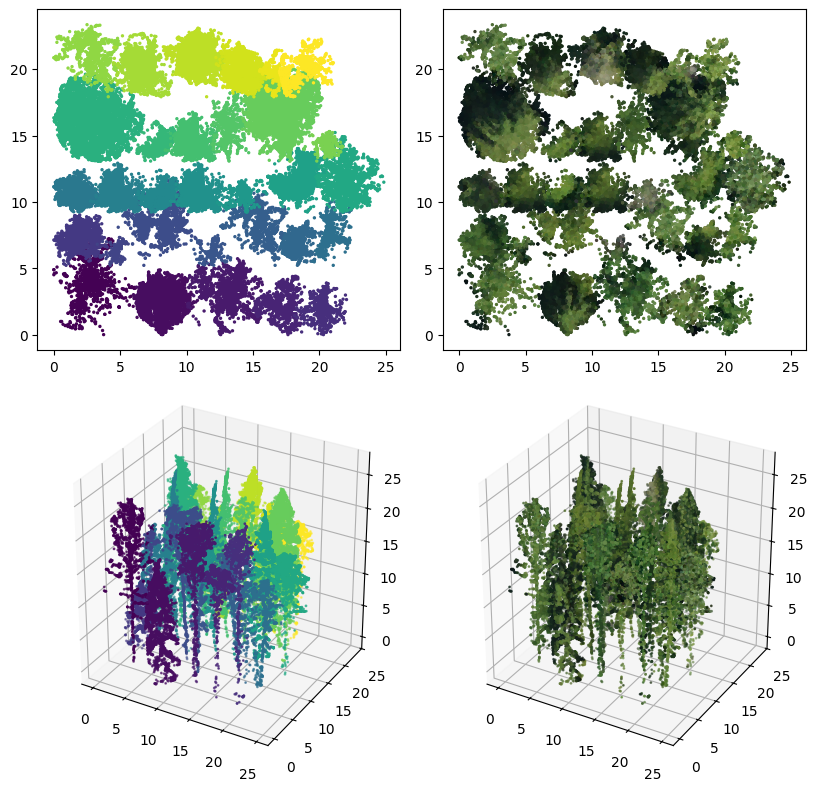
Table 3.3 shows some descriptive statistics for each plot in the field inventory: the number of trees in the plot, average LiDAR point density in points per square meter, and dominant species type. The overall average point density is 37 points per square meter. Exactly half of the plots are predominantly coniferous and half are predominantly deciduous. Figure 3.6 shows two point clouds clipped by plot bounds in 3D, highlighting the differences in canopy structure complexity between predominantly deciduous and coniferous plots. The figure highlights that the forest is indeed dense and mixed, with non-uniform, complex canopy structure.
3.1.1 On using intensity-based features
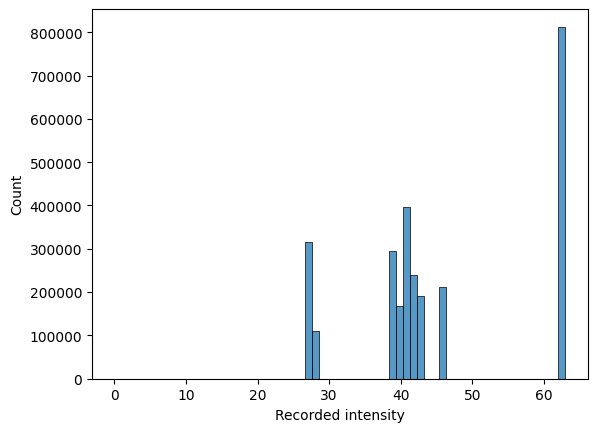
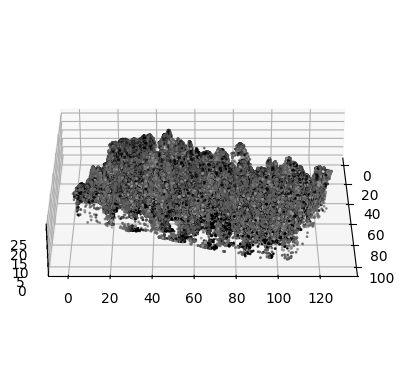
Even though some sources report intensity-based features as some of the most important ones (Shi et al. 2018), the features seem to me unreliable in the context of forestry because of the physics of light reflection. There are simply too many factors that affect the amplitude of the reflected signal, which might be useful when imaging stable targets such as urban environments but become completely unpredictable on highly unstable targets such as trees: they move in the wind in the time span of a single survey, they grow in the time span between repeated surveys, the leaves and branches are angled in every possible way. Moreover, the quality of the recorded intensities highly depends on the used sensor. As an example, Figure 3.7 shows the distribution of intensity values for every point in the Lysva dataset, and shows plot number 10 in 3D with points colored by their recorded intensity. The distribution of intensities seems like an artifact of faulty quantization (the fact that the maximum overall value is 63 makes me suspect it is stored by the hardware using a 6-bit unsigned integer, probably an ad hoc optimization by the sensor vendor). With this distribution in mind, it is not surprising that coloring points by their intensity values results in images that look like noise, and there is no signal to be exploited for predictive modeling.
Some sensors do provide more consistent values. However, relying on intensity-based features limits the applicability of developed models and methods, as any such model would surely fail on data like this.
3.1.2 Comparison to other datasets
Our dataset is in many ways similar to the NewFor benchmark (Eysn et al. 2015). It serves the same purpose and also offers overlapping field survey ground plots and UAV LiDAR point clouds. There are, however, many notable differences. The NewFor benchmark covers much more diverse regions, including ground plots from France, Italy, Switzerland, Austria, and Slovenia, while all our data comes from the same area. The tree species covered by the datasets are also different: both contain spruce and fir, but the NewFor data also has beech, Scots pine, larch, sycamore, and poplar, while ours also has birch, aspen, tilia, alder, and willow. Our dataset has more than twice as many individual trees as the Alpine benchmark, and the forest is denser and more complex, making it more complicated to detect trees in. Our data contains very mild terrain variations, while the slopes of the terrain in Alpine data are very steep, which plays a role during height normalization, since subtraction of steep terrain introduces artificial slope to the points in the canopy, changing the overall shape of the tree. Our dataset has an additional information source – an RGB orthophoto that allows development of algorithms that fuse multimodal data, which, we believe, is a key to success in such complex environments. Our dataset has species labels for every surveyed tree, but only partial coverage of tree heights and no timber volume information at all.
Another similar dataset is the NeonTreeEvaluation Benchmark (Weinstein, Marconi, and White 2022), which offers bounding box annotation for tree detection across a wide range of different forest types. It offers coregistered RGB, LiDAR, and hyperspectral images over 31,000 individual trees. The main difference in the reference data between the NeonTreeEvaluation Benchmark and our dataset is the source: our data comes from a field inventory and thus has additional tree information that can be used in downstream tasks, such as species classification or timber volume prediction, while the NeonTreeEvaluation Benchmark annotations are created from the RGB photo and thus only offer the positions and sized of trees.
Another dataset is the IDTReeS 2020 Competition Data (Graves and Marconi 2020) aimed to develop algorithms for delineation and species classification of individual tree crowns in RGB, LiDAR, and hyperspectral data. It offers bounding box annotations for 1200 individual trees covered by RGB, LiDAR, and hyperspectral images in 3 national forests in the USA. Similarly, the source of the data is annotation of images, not a field inventory.
There are also datasets available that do not have LiDAR point cloud coverage, or use terrestrial LiDAR instead of UAV LiDAR, or use photogrammetric point clouds instead of LiDAR point clouds. We do not mention them here because we specifically focus on UAV LiDAR.
3.2 Individual tree point clouds dataset
The main dataset used for training the models is a collection of point clouds of individual trees, sometimes referred to in this text as tree clouds, extracted manually from larger UAV LiDAR point clouds. The dataset is released into open access, and was originally presented in (Dubrovin and Fortin 2024), although it has been expanded since and now contains twice as many individual trees. It consists of 394 trees, 192 of which are extracted from the previously described Lysva survey, and 202 from other surveys in Perm Krai. The distinction between the parts is important because the Lysva dataset has RGB orthophoto coverage, making it possible to infuse the tree clouds with orthophoto-based features. Thus, for training the tree segmentation networks that rely on these features, the effective size of the dataset is 192 tree clouds, as only the former part is used. However, the whole dataset is used for training regression and classification models that process segmented trees.
Figure 3.8 shows the distribution of species in the individual tree point clouds dataset. The split between coniferous and deciduous trees is almost even: there are 202 coniferous and 193 deciduous trees. There are seven species in total: spruce, birch, aspen, pine, fir, alder, and tilia, with most focus on 4 most important species listed first. Note the presence of pine trees, which are not present in the Lysva field inventory data, and the absence of willow trees. All the pine trees are from other field surveys. Willows are skipped intentionally, since they are of little interest in terms of timber harvesting: they are considered low quality, and their ripening cycle is mismatched with main timber species – when the overall plot is ready to be harvested, the willows are already rotten.
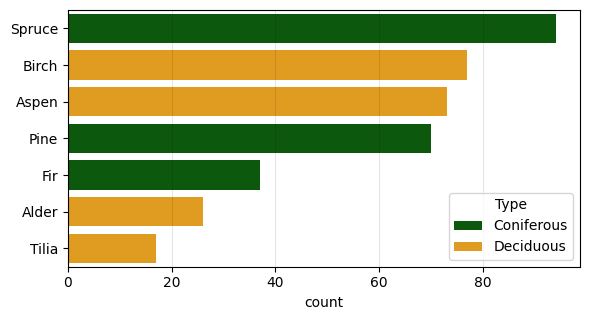
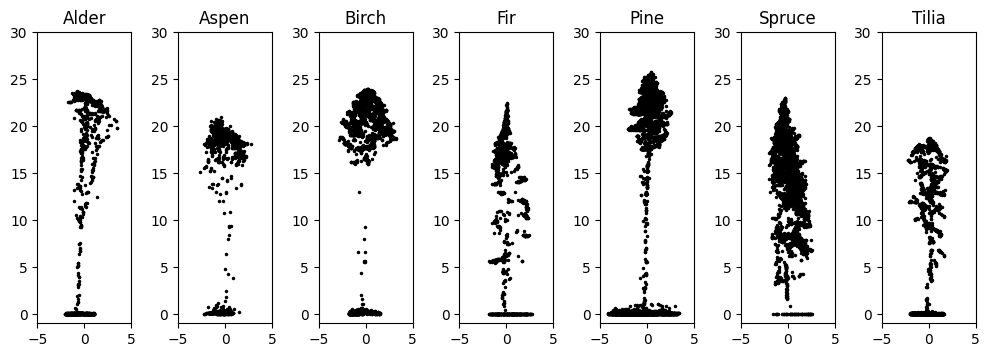
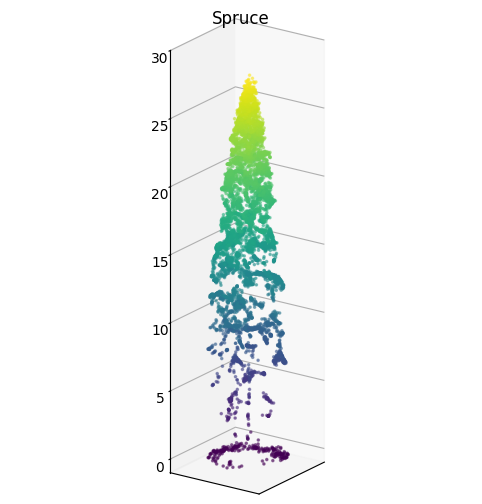
Figure 3.9 is a visualization of the data. It shows a random tree of every species as a 2D scatter plot and a single spruce as a 3D scatter plot with points colored by height. Because the observations are made from above, many trees have the highest concentrations of points at the top of their canopy and a very limited number of points along the trunk. Additionally, slight slopes of the terrain manifest as artificial tilt in some of the trees because of the height normalization of the original point cloud.
An important note is that the extracted trees were not chosen for extraction randomly but were selected by humans based on whether it was possible and relatively easy to separate from the surrounding trees. So there is a selection bias in there favoring the trees that are easily separable, standing outside of large dense clusters. Because of that the trees do not exactly represent what a tree closely surrounded by other trees is like in a point cloud. It is especially apparent in very pronounced trunks of all the visualized trees. In a dense forest, such as the one visualized in Figure 3.6, there is hardly ever enough penetration for such detailed trunk coverage. In fact, as mentioned in the literature review, good coverage of trunks is an immensely useful feature of terrestrial LiDAR surveys, which consistently show very good results using algorithm that segment trees from the trunk up.
3.3 Synthetic forests generated from individual trees
To train tree segmentation models, training data where every point is assigned to an individual tree is required. Data like that are very labor-intensive to label. An alternative way to create such data is by generating it from a set of tree clouds, as the per point labels arise naturally in this case. I used the dataset of individual tree point clouds described in the previous section to generate a synthetic forest to train a tree segmentation PointNet++.
Synthetic forest is generated in patches of set height and width by sampling individual trees from the full set and placing them from left to right, until the set width is extended, then from bottom to top, until the set height is extended. A height threshold is applied to each tree before placing it to remove ground points and non-tree reflections. This results in patches that are slightly bigger than the set size, but that can be cropped into the exact size. This has an added benefit of mimicking cutoff trees at the edges of the patch that are inevitable when the model is applied in a sliding window. The trees can be sampled with or without replacement, but since a set of augmentations described in Section 3.4.2 is applied to each tree individually, exact same tree never occurs in the patch fed to the model even when sampling with replacement. When trees are placed, their planar bounding boxes are tracked to avoid overlap. However, since some overlap might, in fact, be desired to better represent actual forests, a parameter that controls the amount of overlap is added to the dataset generation process. Each tree is also assigned a label, which simply tracks its ordinal number in the patch. An example of a 20 by 20 meter synthetic forest patch with 0.75 meter overlap and 2 meter height threshold is shown in Figure 3.10 from two different perspectives and using two color schemes: the label, i.e. the ordinal ID of the tree within a patch, and RGB color sampled from the orthophoto.
For comparison, a patch of the same size from a real point cloud over one of the plots of the Lysva survey is shown in Figure 3.11.
An alternative approach to creating patches of synthetic forest can be to use a fixed number of trees instead of fixed patch size. However, it poorly correlates with how the final model will be applied: in windows of fixed size, not windows with varying size but fixed number of trees. And size of the patch the model sees is important because the scale is normalized, and using a different patch sizes changes the scaled coordinates and confuses the model that learned to rely on them.
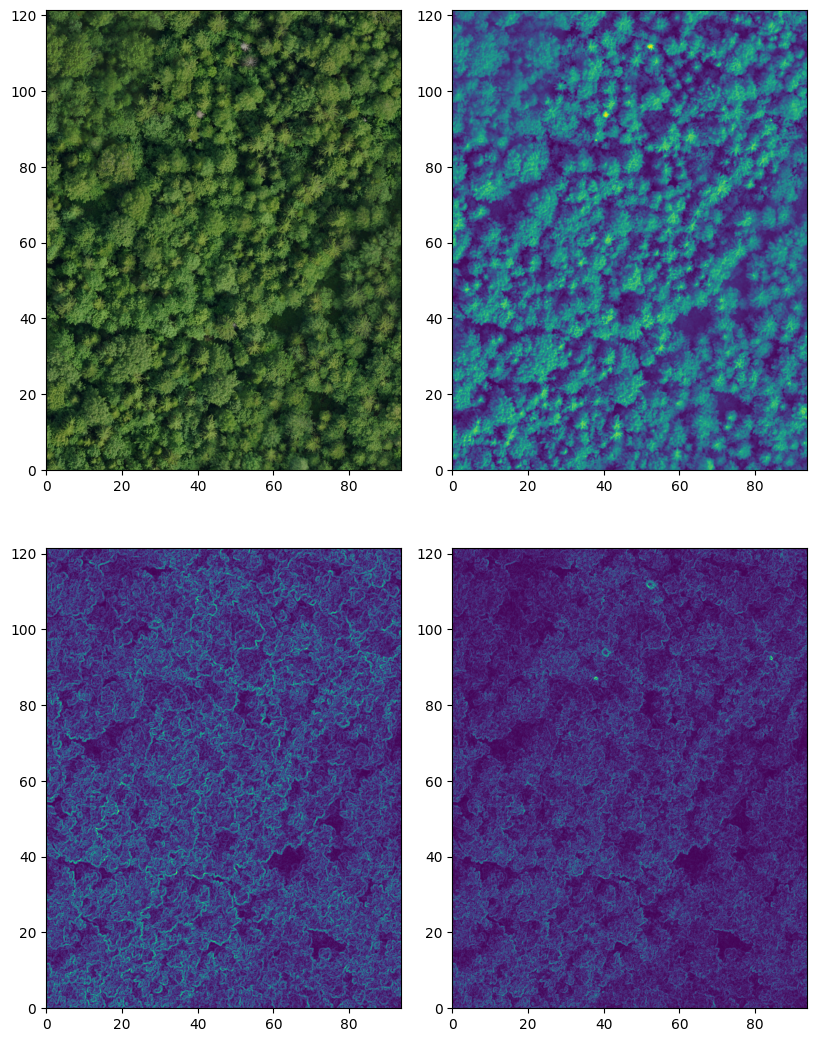
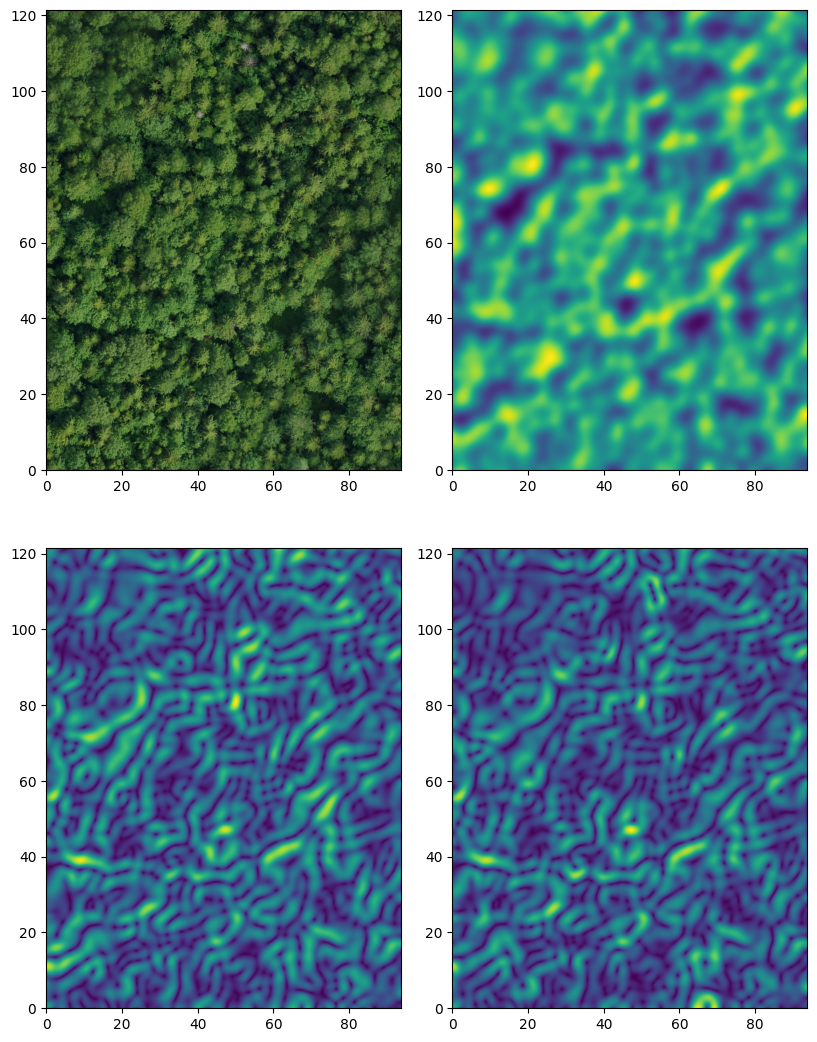
Enriching point clouds using only color information from RGB orthophotos provides limited utility because it adds only local information to the points. As was mentioned in the introduction, one of the aspects of the complementary nature of the two data sources is that images provide continuous representations and capture textures. To enrich the image features with context, they can be preprocessed with feature extractors that encode context into pixel values and thus provide more information for the segmentation network. The feature extractors can be simple algorithms or specialized convolutional network feature extractors. For the same reason a simple PointNet++ is used as the architecture for the tree segmentation network, a simple collection of multi-scale features are used as orthophoto features, including intensity, edge, and texture features, extracted from the orthophotos using the scikit-image Python package. The features are calculated on different scales by applying Gaussian smoothing with varying parameters before calculation. Figure 3.12 shows example features from every mentioned group on a very fine scale. The top left image is the original orthophoto of plot 10 from the Lysva survey, the top right image is the intensity calculated from it, and bottom images are examples of an edge feature and a texture feature. The same features but on a coarser scale are shown in Figure 3.13.
It is worth mentioning that using synthetic data for training comes with potential biases that are important to keep in mind. The biases present in the source dataset can easily become exaggerated. In this case, the selection bias mentioned in Section 3.2 is the main potential culprit. The limited size of the source dataset also limits the variability of the examples, which can easily lead to complex overfitting. In this case, the range of shapes of the trees within each species is small, making it hard to generalize well. Moreover, different species will most likely have different accuracies associated with them. Models trained entirely on synthetic datasets are also a lot harder to properly evaluate. These drawbacks are partially addressed by carefully choosing the augmentations for the training procedure, but they cannot be completely circumvented.
3.4 Training tree segmentation neural networks
The architecture chosen to serve as the tree segmentation network is the PointNet++ (Qi et al. 2017), described in detail in Section 2.2. It is a relatively simple architecture, and further potential quality improvements might be achieved by using more modern and advanced architectures instead. However, the main goal of this thesis was to develop and verify an overall framework, and thus the choice was set on a model that is simple to implement and work with to allow easy experimentation with other parts of the proposed system.
The architecture of the used PointNet++ is similar to the segmentation architecture shown in Figure 2.3. The main differences from the shown architecture are the use of one more stacked set abstraction layer to make the network deeper, and the use of a regression head that predicts a continuous value for each point instead of a classification head that predicts per-point class scores, since the model needs to assign a unique ID to every tree in the patch. The three stacked set abstraction layers have the proportions of points sampled set to 0.75, 0.5, and 0.5, and neighborhood radii for feature aggregation set to 0.1, 0.2, and 0.4. Note that the scale of the input is normalized (see next section for details), so the radii are not in meters. The final model has 30 million trainable parameters.
3.4.1 Coordinate and feature normalization
It’s a well established practice to scale the inputs to neural networks that is known to improve the speed and accuracy of gradient descent convergence (Bishop 2006). Before going through the network, a set of augmentations and transformations is applied to each synthetic forest patch. The augmentations are described in detail with visualized examples in Section 3.4.2. The transformations include scale and feature normalization – the coordinates are centered and normalized to the interval \((-1, 1)\) and the features are normalized to the interval \((-1, 1)\) without centering.
3.4.2 Data augmentation
The primary objective of data augmentation is to enhance the quantity, quality, and variety of data used for training (Mumuni and Mumuni 2022). This is especially important when the sizes of the available datasets are limited, like in the case of the individual trees data that is the base of the synthetic forest datasets. Carefully selected augmentations allow increasing the effective dataset size. However, it is important to pay attention that the chosen augmentations keep the transformed examples semantically equivalent to the original. A readily understandable example of a bad augmentation in the task of digit classification, which is often used as the “hello world” of deep learning with the MNIST dataset of handwritten digits (Deng 2012), is a vertical flip, as most digits lose meaning when upside down. A flip is also a bad augmentation example for a synthetic forest patch described in Section 3.3, as it changes the order of the trees within a patch, thus breaking the labels that are assumed to increase in a specific pattern.
In the scenario when the data for is created by combining several smaller inputs, there is a possibility of applying augmentations on two different scales. The most simple approach is to treat a synthetic forest patch as a whole and apply augmentations directly to it. However, it is also possible to apply per-tree augmentations, effectively increasing the size of the underlying tree set from which synthetic forest patches constructed. Only the latter kind are used for training the tree segmentation network.
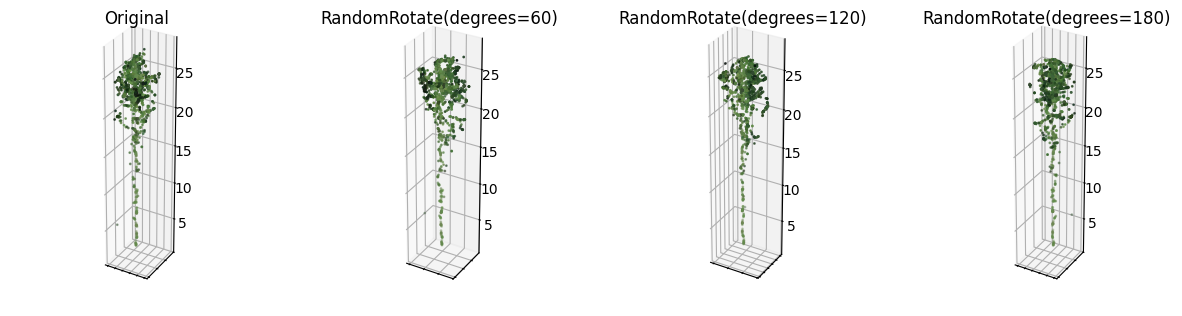
The first transformation that changes the shape but does not affect any semantics for an individual tree is a random rotation around the vertical axis. A tree remains completely the same when rotated, but the coordinates of all points change. Figure 3.14 shows the effect of applying random rotation transformation of different magnitudes to a single aspen tree. For visualization purposes, the rotation is forced to apply with full magnitude for every parameter. During training, the angle is uniformly sampled from the specified range. For the final tree segmentation model, the range is set to \([-180, 180]\) degrees, as no amount of rotation breaks the semantics.
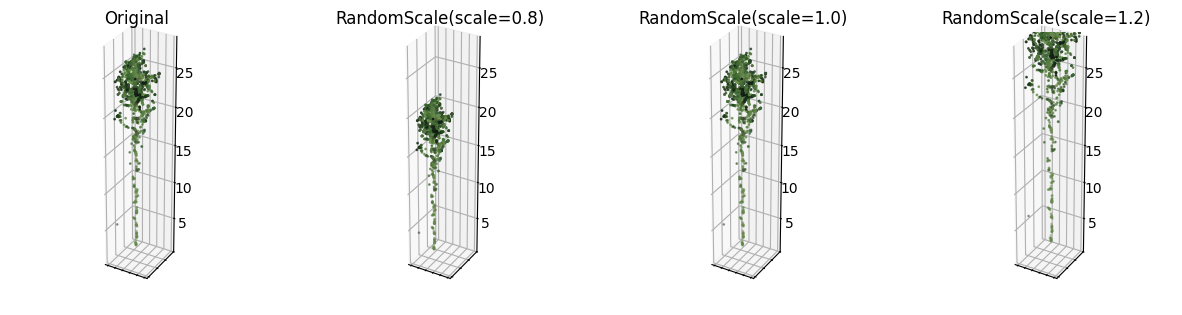
Another transformation that keeps the tree the same but changes the coordinates of the points is random scaling. It simply multiplies the coordinates by a scaling factor, making the tree larger or smaller in all directions. Unlike random rotation around the vertical axis, however, the range needs to be chosen much more carefully, as there is a possibility of making unrealistically large or small trees that would confuse the model during training. Figure 3.15 shows the effect of applying random scale transformation to a single aspen tree. Again, for purposes of visualization, the scale is forced to apply with full magnitude. During training, the scale is uniformly sampled from the specified range. For the final tree segmentation model, the range is set to \([0.8, 1.2]\).
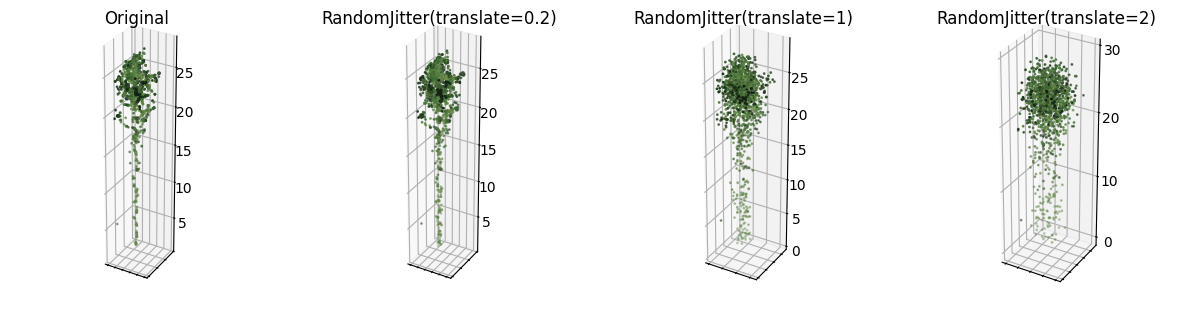
Another way to change the positions is to slightly translate each point for a random distance in a random direction. That transformation is commonly referred to as random jitter. Since LiDAR sensors have limited spatial accuracy, introducing random translations within the accuracy range should not have any effect on the result of tree segmentation. Going further, small translations even outside the accuracy range make sense, since they have very limited effect on the overall shape of the tree. Figure 3.16 shows this effect on a single aspen tree. The amount of translation is uniformly sampled independently for each point from a set range. Note that the random jitter augmentation is applied before the scale normalization. It matters because the augmentation’s only parameter is the translation range, which depends on the scale. The parameters on the figure are thus in the original coordinate units – meters. Note how the shape of the tree almost does not change when the maximum range is set to 20 centimeters, and starts to become fuzzy and loose shape at 1 meter and higher. For the final tree segmentation model, the maximum translation is set to 30 centimeters.
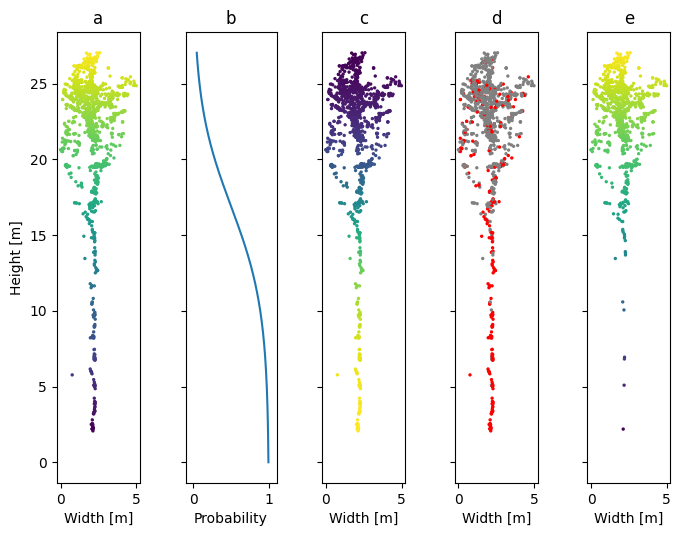
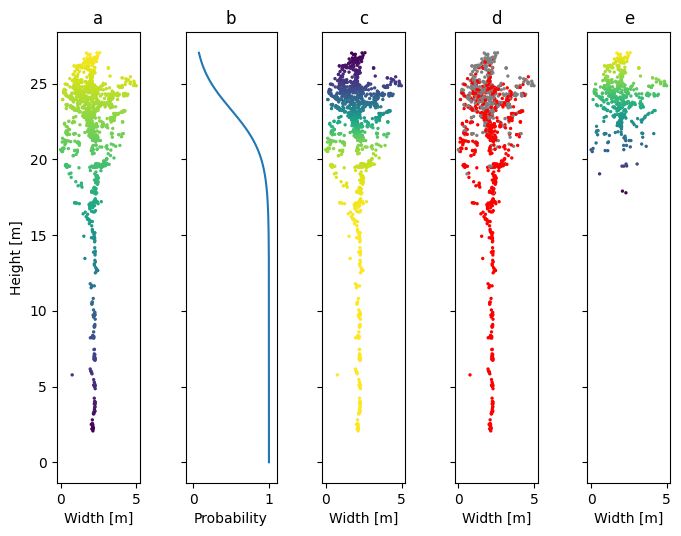
Another useful effect augmentations can provide is to make synthetic data look more like real data. As was mentioned in Section 3.2, there is a selection bias in the dataset of individual trees: the trees that are easiest to manually separate are exponentially more likely to end up in the data. As such, the tree clouds in the individual tree dataset are significantly different from trees of the same species with similar sizes and shapes, but standing in dense clusters. One of the most important differences is that almost all the tree clouds have trunks, while in actual forest, dense canopy cover blocks most pulses and the trunk representation is very poor. One way to mitigate that issue is to apply a height-dependent dropout function to each tree cloud. For that purpose a probability threshold function that is around zero for the highest points of the tree and quickly ramps up to almost one for the lowest points is needed. An example function that satisfies these criteria is a modified sigmoid:
\[ \text{threshold}(z) = \big[1 + e^{z \times \text{scale} + \text{shift}}\big]^{-1}, \]
where \(z\) is the height normalized to \([0, 1]\) and reversed by subtraction from 1, \(\text{scale}\) and \(\text{shift}\) are hyperparameters that control the shape of the curve. Changing \(\text{scale}\) controls how steep is the climb from 0 to 1: the larger, the steeper. Changing \(\text{shift}\) controls the position of the climb: the larger, the lower. Figure 3.17 shows an example of applying such dropout function to a single aspen tree, and Figure 3.18 show the same tree with more aggressive parameters, resulting in much more points being dropped from the tree cloud.
All the augmentation are applied on the fly right before the examples are loaded into GPU memory and passed through the network.
3.4.3 Other training parameters
Mean absolute error is used as a loss function. Some experiments have shown improvements when using a custom loss function that modifies the mean absolute error loss by weighting it reversely proportional to the distance of the tree centroid. The idea of the modification is to make the network focus more on points closer to the center of each tree, as these points are much less likely to be overlapping with the crowns of adjacent trees.
The batch size is limited by the available GPU device memory, and in the described setup competes for memory space with the synthetic forest patch dimensions used in the training dataset. The preference is given to the size of the patch, so the batch size is set to 1, but is compensated for by using gradient accumulation steps – updates to the model parameters are made after the gradient is accumulated for a set number of iterations. This slows down the training, but enables usage of larger batches when there is not enough memory to fit them, making the training procedure overall more stable.
Early stopping (Prechelt 1998) is set up to terminate training early if there is no improvement in average validation loss in a set number of epochs. This makes sure that valuable GPU time is not wasted on continuing training models that are likely to have started overfitting.
Model checkpointing is set up as well. After each training epoch, when the average validation loss and accuracy are calculated, the model state is saved to disk if it’s current accuracy is better than the last saved one, where accuracy is the proportion of points for which the rounded integer label is correct. This makes sure that the best performing model can always be recovered, even if the training process was run for too long and the latest model is not the best one.
The learning rate schedule is set to follow a fast linear warm up and slow linear decay. Learning rate is set to ramp up from 0.001 to 0.01 in a span of 2 epochs, and then decay back to 0.001 in a span of 30 epochs. Adam optimizer is used (Kingma and Ba 2014).
Training was performed on an NVIDIA A100 GPU with 80 Gb of memory. Inference, depending on the point density of the input, might work even on a much smaller GPU like Tesla T4 with 16 Gb of memory. GPUs of this size are available with limits on usage for free on services like Google Colab and Kaggle.
3.4.4 On implementation of PointNet++
As mentioned in the introduction, the deep learning code, including the code for PointNet++, is implemented using the PyTorch Geometric library designed for writing and training graph neural networks. This makes the implementation not exactly the same as described in the PointNet papers. The main ideas, namely local feature learning in a k-nearest neighbors neighborhood and max pooling for permutation-invariant aggregation, are there. Input transform and feature transform networks are not defined explicitly, but networks that process features learn to perform a similar function.
3.5 Training segmented trees processing models
To predict per-tree forest attributes from a segmented point cloud, a set of specialized regression and classification models is trained on the tree clouds. These specialized models are classic machine learning models that operate on most common metrics described in the literature overview chapter. As mentioned in the literature overview, common features used for machine learning on point clouds are based on the eigenvalues of the covariance matrix of the point coordinates, calculated either for an entire cloud, or per-point in a neighborhood around it. These features include linearity, planarity, scatter, that aim to indicate the presence of linear, planar, or volumetric structures, and also omnivariance, anisotropy, eigentropy, the sum of eigenvalues, and curvature. The features are defined as follows, with eigenvalues sorted in descending order such that \(\lambda_1 \ge \lambda_2 \ge \lambda_3\):
\[ \begin{aligned} \text{linearity} &= \frac{\lambda_1 - \lambda_2}{\lambda_1} \\ \text{planarity} &= \frac{\lambda_2 - \lambda_3}{\lambda_1} \\ \text{scatter} &= \frac{\lambda_3}{\lambda_1} \\ \text{omnivariance} &= \sqrt[3]{\lambda_1\lambda_2\lambda_3} \\ \text{anisotropy} &= \frac{\lambda_1 - \lambda_3}{\lambda_1} \\ \text{eigentropy} &= -\sum_{i=1}^{3} \lambda_i \ln(\lambda_i) \\ \text{sum of eigenvalues} &= \lambda_1 + \lambda_2 + \lambda_3 \\ \text{curvature} &= \frac{\lambda_3}{\lambda_1 + \lambda_2 + \lambda_3} \\ \end{aligned} \]
Another common set of features, especially popular in forestry applications, are various statistics that describe the height distribution of points within the neighborhood or the cloud. They include maximum and average height, standard deviation, kurtosis, skew, and entropy of the height distribution, percentage of points above the mean and each of the deciles of height and the deciles of height themselves. The features are calculated for the entire tree cloud, effectively reducing each tree to a collection of metrics, resulting in a tabular dataset. In this form, the dataset is used to train the models.
In Dubrovin and Fortin (2024), we propose a way to help build intuition into the meaning of some of the less obvious features by visualizing individual trees on a different end of the range of the feature’s values. Figure 3.19 shows is an example of such visualization, showing the effect of the shape of spruce on omnivariance and the effect of the shape of aspen on percent of points above mean height. Note the presence of ground points, which are filtered out before calculating features for the models.
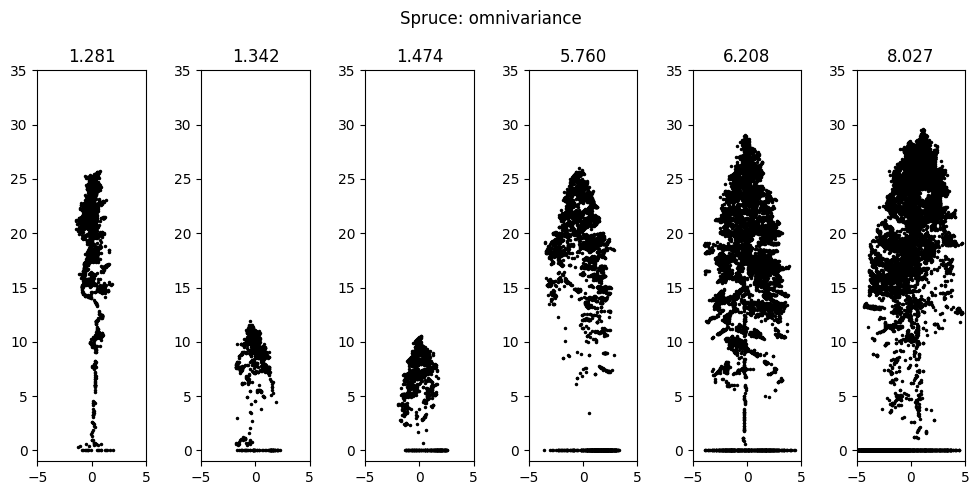
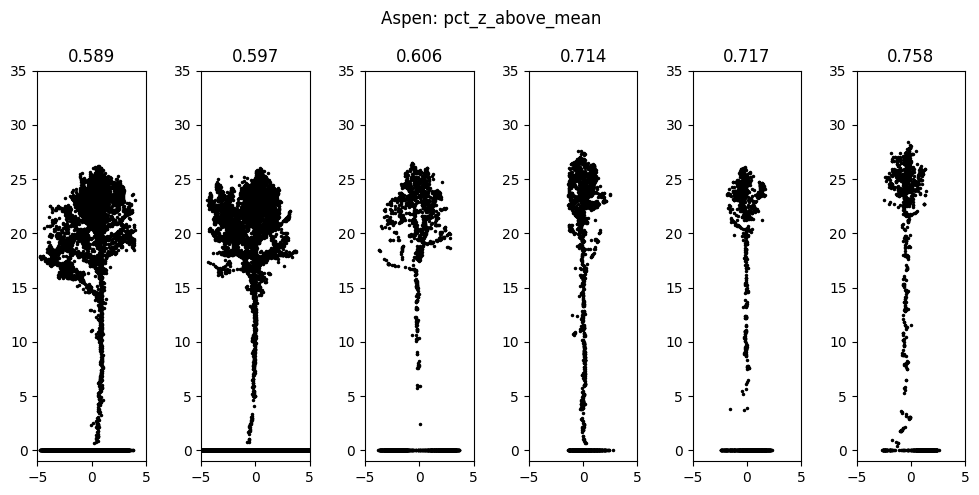
The feature set is thinned by using sequential feature selection: a greedy approach that selects the best feature according to 5-fold cross-validation accuracy on every iteration until a set number of features is selected. The models are trained on 20 best features selected this way.
To make the trees more closely resemble the trees standing in dense clusters, the same height-dependent dropout function that is used for augmenting synthetic forests is used. This dropout, together with a small amount of random jitter, is also used to create additional samples for training the models, as the original dataset size is very small. Great care is taken to only create additional samples within the training set, to avoid any data leakage. Every training set sample is repeated 3 times with random jitter with maximum amplitude of 20 cm and a dropout applied.
Two models are used as proof of concept for the proposed framework: a classifier that predicts the tree species, and a regressor that estimates a tree’s diameter at breast height. Random Forest models are used in both cases. The number of trees is set to 200. For the classification model, class weights are assigned to every example that are inversely proportional to the class frequency in the data during model fitting.
3.6 Matching detections to field inventory ground truth
To evaluate the results of any tree detection system against field inventory data, an automated and deterministic method for matching detected tree candidates to the ground truth trees is needed. It should determine which ground truth trees, if any, the detected candidates correspond to. It should also classify both the trees and the candidates as either a true positive, meaning that the ground truth tree was successfully detected, a false negative, meaning that a ground truth tree was not detected, or a false positive, meaning a tree was detected when there is none.
I use the same matching procedure that is described and implemented in Dubrovin, Fortin, and Kedrov (2024). It considers the locations and heights of the trees, and falls back to using only locations when the height is not available for the ground truth tree. It is parametrized by the maximum allowed 2D distance and the maximum height difference between a detected and a ground truth tree to consider them a match. First, it constructs a distance matrix between the ground truth tree locations and the detected candidates and filters out the pairs for which the distance is larger than the allowed maximum. It then iterates over the remaining pairs in the order of increasing distance, and marks the pairs with suitable heights in which both trees are not yet assigned a class as a true positive. The pairs in which one of the trees is already assigned a class are marked as either a false positive or a false negative, and the pairs in which both trees are assigned a class are skipped. Finally, it marks all unmatched ground truth trees as false negatives, and all unmatched candidate trees as false positives.
Based on the results of the matching algorithm, a set of metrics that are often used to evaluate the results of tree detection can be calculated. The same metrics are usually used for evaluation in classification problems and thus are well-known. The first commonly used metric is recall, which is the proportion of the ground truth trees that were detected. The second metric is precision, which is the proportion of candidates that are correct. Both are important, and describe a detection system from different perspectives. To combine them into a single metric, \(F_1\)-score is often used, which is the harmonic mean of precision and recall that provide a balanced measure of the system performance. The formulas for the metrics are as follows:
\[ \text{recall} = \frac{N_{\text{true positives}}}{N_\text{trees}} = \frac{N_{\text{true positives}}}{N_{\text{true positives}} + N_{\text{false negatives}}} \]
\[ \text{precision} = \frac{N_{\text{true positives}}}{N_\text{candidates}} = \frac{N_{\text{true positives}}}{N_{\text{true positives}} + N_{\text{false positive}}} \]
\[ F_1\text{-score} = 2 \times \frac{\text{precision} \times \text{recall}}{\text{precision} + \text{recall}} \]
Another commonly used metric to evaluate the results of tree detection approaches is the average distance between a detected and a ground truth tree. This metric, however, has limitations that are important to keep in mind when analyzing the results. The first important limitation is that its value is limited in how low it can get by the difference in nature of the compared detections and ground truth field inventory. During the inventory, the trees’ coordinates are recorded at their trunks, approximately at breast height, which is almost at the ground level compared to the height of the trees. The detections, on the other hand, happen with the perspective from above, and correspond to tree tops. Planar distance between the bottom of the trunk and the top of the canopy can be significant, especially if trees are even slightly tilted, or for broadleaf species with wide and irregular canopies, or both. So the average distance between predicted trees and their ground truth counterparts will rarely be zero, even for a perfect detection system. The other limitation it that that distance is also limited from above by the parameters used for the matching algorithm. As mentioned, one of the parameters is the maximum distance allowed between a candidate and an actual tree to consider them a match. Thus, the average distance metric is limited from both directions, but in ways that are not immediately obvious. I do calculate and report it in the results section, but the reader is advised to keep the limitations in mind.
3.7 Application of the framework
The framework is applied in two steps. First, the tree segmentation network is applied in a sliding window of the same size that was used for patch generation during its training, with overlap to be able to combine the results into a single prediction. The continuous predictions of the regression model are rounded to get the integer labels for every point. The results are merged to create a single point cloud, and a postprocessing routine aimed to transform per-window tree IDs to global tree IDs is run. It traces the overlapping points to find the labels that need to be updated in the later window, and adds a large number to predictions with remaining labels in the later window. Second, the segments identified by predicted integer labels are extracted, selected feature sets are calculated for each one, and each one is passed through the collection of attribute prediction models to get per-tree predictions.